Linux
Introduction to Linux Operating System (OS): What is Linux?
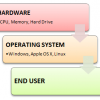
What is Linux? LINUX is an operating system or a kernel distributed under an open-source license....
We have discussed various pos_tag in the previous section. In this particular tutorial, you will study how to count these tags. Counting tags are crucial for text classification as well as preparing the features for the Natural language-based operations. I will be discussing with you the approach which gtupapers followed while preparing code along with a discussion of output. Hope this will help you.
How to count Tags:
Here first we will write working code and then we will write different steps to explain the code.
from collections import Counter import nltk text = " gtupapers is one of the best sites to learn WEB, SAP, Ethical Hacking and much more online." lower_case = text.lower() tokens = nltk.word_tokenize(lower_case) tags = nltk.pos_tag(tokens) counts = Counter( tag for word, tag in tags) print(counts)
Output:
Counter({'NN': 5, ',': 2, 'TO': 1, 'CC': 1, 'VBZ': 1, 'NNS': 1, 'CD': 1, '.': 1, 'DT': 1, 'JJS': 1, 'JJ': 1, 'JJR': 1, 'IN': 1, 'VB': 1, 'RB': 1})
Elaboration of the code

Output = [('gtupapers', 'NN'), ('is', 'VBZ'), ('one', 'CD'), ('of', 'IN'), ('the', 'DT'), ('best', 'JJS'), ('site', 'NN'), ('to', 'TO'), ('learn', 'VB'), ('web', 'NN'), (',', ','), ('sap', 'NN'), (',', ','), ('ethical', 'JJ'), ('hacking', 'NN'), ('and', 'CC'), ('much', 'RB'), ('more', 'JJR'), ('online', 'JJ')] Frequency Distribution is referred to as the number of times an outcome of an experiment occurs. It is used to find the frequency of each word occurring in a document. It uses FreqDistclass and defined by the nltk.probabilty module.
A frequency distribution is usually created by counting the samples of repeatedly running the experiment. The no of counts is incremented by one, each time. E.g.
freq_dist = FreqDist()
for the token in the document:
freq_dist.inc(token.type())
For any word, we can check how many times it occurred in a particular document. E.g.
We will write a small program and will explain its working in detail. We will write some text and will calculate the frequency distribution of each word in the text.
import nltk a = "gtupapers is the site where you can find the best tutorials for Software Testing Tutorial, SAP Course for Beginners. Java Tutorial for Beginners and much more. Please visit the site gtupapers.com and much more." words = nltk.tokenize.word_tokenize(a) fd = nltk.FreqDist(words) fd.plot()

Explanation of code:
Please visualize the graph for a better understanding of the text written

Frequency distribution of each word in the graph
NOTE: You need to have matplotlib installed to see the above graph
Observe the graph above. It corresponds to counting the occurrence of each word in the text. It helps in the study of text and further in implementing text-based sentimental analysis. In a nutshell, it can be concluded that nltk has a module for counting the occurrence of each word in the text which helps in preparing the stats of natural language features. It plays a significant role in finding the keywords in the text. You can also extract the text from the pdf using libraries like extract, PyPDF2 and feed the text to nlk.FreqDist.
The key term is "tokenize." After tokenizing, it checks for each word in a given paragraph or text document to determine that number of times it occurred. You do not need the NLTK toolkit for this. You can also do it with your own python programming skills. NLTK toolkit only provides a ready-to-use code for the various operations.
Counting each word may not be much useful. Instead one should focus on collocation and bigrams which deals with a lot of words in a pair. These pairs identify useful keywords to better natural language features which can be fed to the machine. Please look below for their details.
Collocations are the pairs of words occurring together many times in a document. It is calculated by the number of those pair occurring together to the overall word count of the document.
Consider electromagnetic spectrum with words like ultraviolet rays, infrared rays.
The words ultraviolet and rays are not used individually and hence can be treated as Collocation. Another example is the CT Scan. We don't say CT and Scan separately, and hence they are also treated as collocation.
We can say that finding collocations requires calculating the frequencies of words and their appearance in the context of other words. These specific collections of words require filtering to retain useful content terms. Each gram of words may then be scored according to some association measure, to determine the relative likelihood of each Ingram being a collocation.
Collocation can be categorized into two types-
Bigrams and Trigrams provide more meaningful and useful features for the feature extraction stage. These are especially useful in text-based sentimental analysis.
import nltk text = "gtupapers is a totally new kind of learning experience." Tokens = nltk.word_tokenize(text) output = list(nltk.bigrams(Tokens)) print(output)
Output
[('gtupapers', 'is'), ('is', 'totally'), ('totally', 'new'), ('new', 'kind'), ('kind', 'of'), ('of', 'learning'), ('learning', 'experience'), ('experience', '.')]Sometimes it becomes important to see a pair of three words in the sentence for statistical analysis and frequency count. This again plays a crucial role in forming NLP (natural language processing features) as well as text-based sentimental prediction.
The same code is run for calculating the trigrams.
import nltk text = “gtupapers is a totally new kind of learning experience.” Tokens = nltk.word_tokenize(text) output = list(nltk.trigrams(Tokens)) print(output)
Output
[('gtupapers', 'is', 'totally'), ('is', 'totally', 'new'), ('totally', 'new', 'kind'), ('new', 'kind', 'of'), ('kind', 'of', 'learning'), ('of', 'learning', 'experience'), ('learning', 'experience', '.')]
What is Linux? LINUX is an operating system or a kernel distributed under an open-source license....
Programmers spend most of their days on a computer designing, writing, and testing code. This...
Ultrawide monitors generally have 1/3rd more screen space in width than a normal widescreen...
Online learning is among the top trends that have picked up swiftly in this digital age. Its...
What is a Stack? A stack is a special area of computer's memory which stores temporary variables...
Python code editors are designed for the developers to code and debug program easily. Using these...