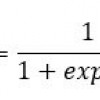Blog

10+ BEST Video Players for Mac (2021)
Video players are a kind of media player that can play video data from varieties of sources local...
In Greedy Algorithm a set of resources are recursively divided based on the maximum, immediate availability of that resource at any given stage of execution.
To solve a problem based on the greedy approach, there are two stages
These stages are covered parallelly in this Greedy algorithm tutorial, on course of division of the array.
To understand the greedy approach, you will need to have a working knowledge of recursion and context switching. This helps you to understand how to trace the code. You can define the greedy paradigm in terms of your own necessary and sufficient statements.
Two conditions define the greedy paradigm.
With the theorizing continued, let us describe the history associated with the Greedy search approach.
In this Greedy algorithm tutorial, you will learn:
Here is an important landmark of greedy algorithms:
Logic in its easiest form was boiled down to "greedy" or "not greedy". These statements were defined by the approach taken to advance in each algorithm stage.
For example, Djikstra's algorithm utilized a stepwise greedy strategy identifying hosts on the Internet by calculating a cost function. The value returned by the cost function determined whether the next path is "greedy" or "non-greedy".
In short, an algorithm ceases to be greedy if at any stage it takes a step that is not locally greedy. The Greedy problems halt with no further scope of greed.
The important characteristics of a Greedy method algorithm are:
Here are the reasons for using the greedy approach:
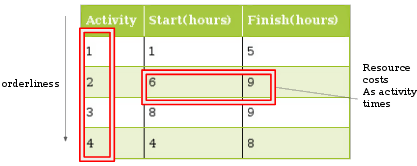
In the activity scheduling example, there is a "start" and "finish" time for every activity. Each Activity is indexed by a number for reference. There are two activity categories.
The total duration gives the cost of performing the activity. That is (finish - start) gives us the durational as the cost of an activity.
You will learn that the greedy extent is the number of remaining activities you can perform in the time of a considered activity.
STEP 1)
Scan the list of activity costs, starting with index 0 as the considered Index.
STEP 2)
When more activities can be finished by the time, the considered activity finishes, start searching for one or more remaining activities.
STEP 3)
If there are no more remaining activities, the current remaining activity becomes the next considered activity. Repeat step 1 and step 2, with the new considered activity. If there are no remaining activities left, go to step 4.
STEP 4 )
Return the union of considered indices. These are the activity indices that will be used to maximize throughput.
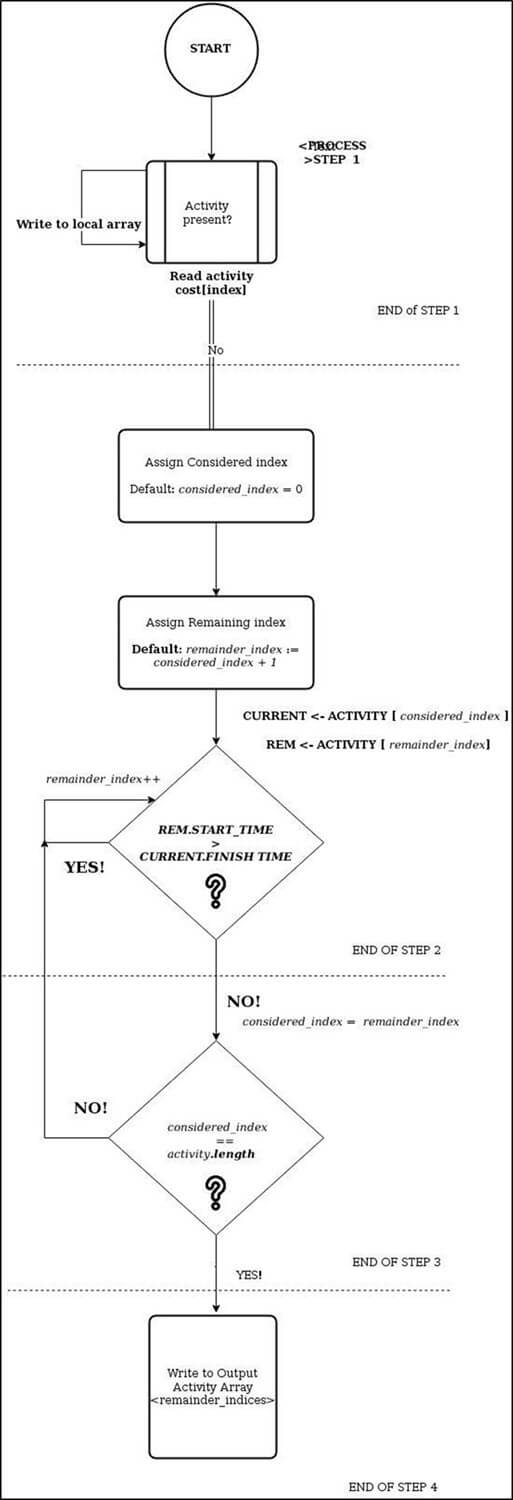
#include<iostream> #include<stdio.h> #include<stdlib.h> #define MAX_ACTIVITIES 12
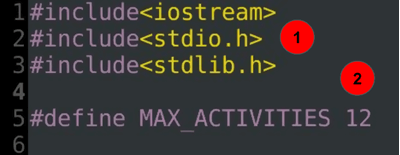
Explanation of code:
using namespace std;
class TIME
{
public:
int hours;
public: TIME()
{
hours = 0;
}
};
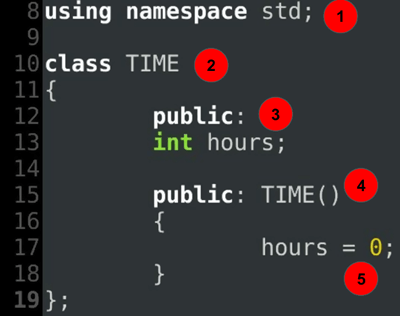
Explanation of code:
class Activity
{
public:
int index;
TIME start;
TIME finish;
public: Activity()
{
start = finish = TIME();
}
};

Explanation of code:
class Scheduler
{
public:
int considered_index,init_index;
Activity *current_activities = new Activity[MAX_ACTIVITIES];
Activity *scheduled;

Explanation of code:
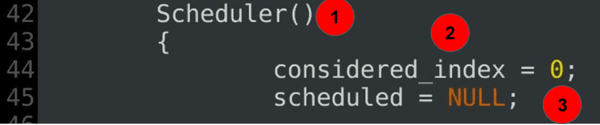
Scheduler()
{
considered_index = 0;
scheduled = NULL;
...
...
Explanation of code:
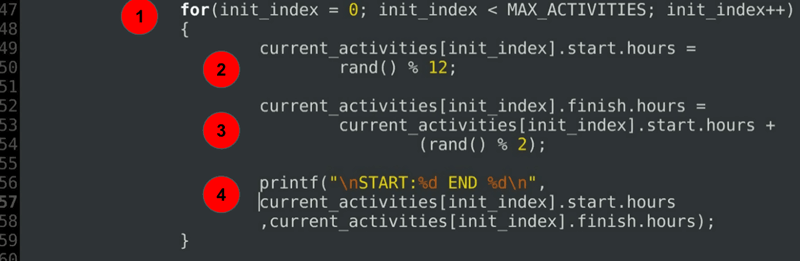
for(init_index = 0; init_index < MAX_ACTIVITIES; init_index++)
{
current_activities[init_index].start.hours =
rand() % 12;
current_activities[init_index].finish.hours =
current_activities[init_index].start.hours +
(rand() % 2);
printf("\nSTART:%d END %d\n",
current_activities[init_index].start.hours
,current_activities[init_index].finish.hours);
}
…
…
Explanation of code:
public: Activity * activity_select(int); };

Explanation of code:
Activity * Scheduler :: activity_select(int considered_index)
{
this->considered_index = considered_index;
int greedy_extent = this->considered_index + 1;
…
…

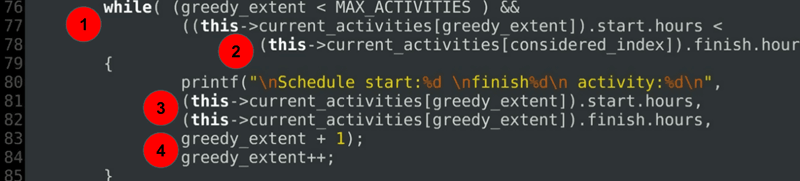
Activity * Scheduler :: activity_select(int considered_index)
{
while( (greedy_extent < MAX_ACTIVITIES ) &&
((this->current_activities[greedy_extent]).start.hours <
(this->current_activities[considered_index]).finish.hours ))
{
printf("\nSchedule start:%d \nfinish%d\n activity:%d\n",
(this->current_activities[greedy_extent]).start.hours,
(this->current_activities[greedy_extent]).finish.hours,
greedy_extent + 1);
greedy_extent++;
}
…
...
Explanation of code:
...
if ( greedy_extent <= MAX_ACTIVITIES )
{
return activity_select(greedy_extent);
}
else
{
return NULL;
}
}

Explanation of code:
int main()
{
Scheduler *activity_sched = new Scheduler();
activity_sched->scheduled = activity_sched->activity_select(
activity_sched->considered_index);
return 0;
}

Explanation of code:
Output:
START:7 END 7 START:9 END 10 START:5 END 6 START:10 END 10 START:9 END 10 Schedule start:5 finish6 activity:3 Schedule start:9 finish10 activity:5
It is not suitable for Greedy problems where a solution is required for every subproblem like sorting.
In such Greedy algorithm practice problems, the Greedy method can be wrong; in the worst case even lead to a non-optimal solution.
Therefore the disadvantage of greedy algorithms is using not knowing what lies ahead of the current greedy state.
Below is a depiction of the disadvantage of the Greedy method:
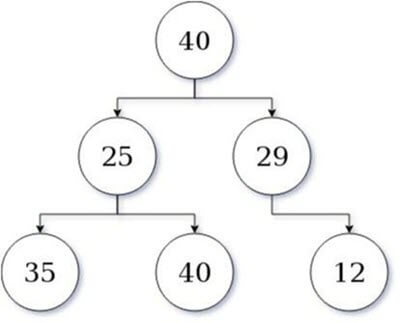
In the greedy scan shown here as a tree (higher value higher greed), an algorithm state at value: 40, is likely to take 29 as the next value. Further, its quest ends at 12. This amounts to a value of 41.
However, if the algorithm took a sub-optimal path or adopted a conquering strategy. then 25 would be followed by 40, and the overall cost improvement would be 65, which is valued 24 points higher as a suboptimal decision.
Most networking algorithms use the greedy approach. Here is a list of few Greedy algorithm examples:
To summarize, the article defined the greedy paradigm, showed how greedy optimization and recursion, can help you obtain the best solution up to a point. The Greedy algorithm is widely taken into application for problem solving in many languages as Greedy algorithm Python, C, C#, PHP, Java, etc. The activity selection of Greedy algorithm example was described as a strategic problem that could achieve maximum throughput using the greedy approach. In the end, the demerits of the usage of the greedy approach were explained.
Video players are a kind of media player that can play video data from varieties of sources local...
What is SAS? SAS stands for S tatistical A nalysis S oftware which is used for Data Analytics. It helps...
Registry cleaner software cleans up your Windows registry. It removes redundant registry entries,...
What is System Software? System Software is a set of programs that control and manage the...
What is Logistic regression? Logistic regression is used to predict a class, i.e., a probability. Logistic...
What is Jenkins Pipeline? Jenkins Pipeline is a combination of plugins that supports integration and...