SQLite

Top 20 SQLite Interview Questions & Answers
Download PDF 1) Explain what is SQLite? SQLite is a mostly ACID compliant relational database...
Indexing is a data structure technique which allows you to quickly retrieve records from a database file. An Index is a small table having only two columns. The first column comprises a copy of the primary or candidate key of a table. Its second column contains a set of pointers for holding the address of the disk block where that specific key value stored.
An index -
In this DBMS Indexing tutorial, you will learn:
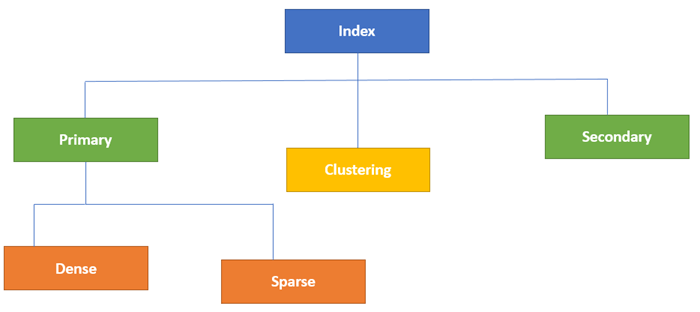
Indexing in Database is defined based on its indexing attributes. Two main types of indexing methods are:
Primary Index is an ordered file which is fixed length size with two fields. The first field is the same a primary key and second, filed is pointed to that specific data block. In the primary Index, there is always one to one relationship between the entries in the index table.
The primary Indexing in DBMS is also further divided into two types.
In a dense index, a record is created for every search key valued in the database. This helps you to search faster but needs more space to store index records. In this Indexing, method records contain search key value and points to the real record on the disk.
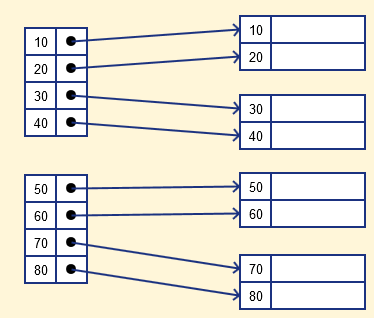
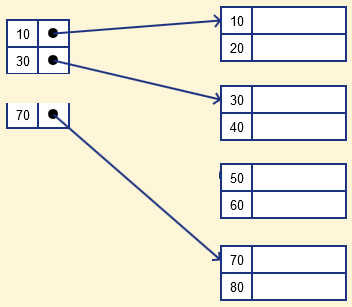
It is an index record that appears for only some of the values in the file. Sparse Index helps you to resolve the issues of dense Indexing in DBMS. In this method of indexing technique, a range of index columns stores the same data block address, and when data needs to be retrieved, the block address will be fetched.
However, sparse Index stores index records for only some search-key values. It needs less space, less maintenance overhead for insertion, and deletions but It is slower compared to the dense Index for locating records.
Below is an database index Example of Sparse Index
The secondary Index in DBMS can be generated by a field which has a unique value for each record, and it should be a candidate key. It is also known as a non-clustering index.
This two-level database indexing technique is used to reduce the mapping size of the first level. For the first level, a large range of numbers is selected because of this; the mapping size always remains small.
Let's understand secondary indexing with a database index example:
In a bank account database, data is stored sequentially by acc_no; you may want to find all accounts in of a specific branch of ABC bank.
Here, you can have a secondary index in DBMS for every search-key. Index record is a record point to a bucket that contains pointers to all the records with their specific search-key value.

In a clustered index, records themselves are stored in the Index and not pointers. Sometimes the Index is created on non-primary key columns which might not be unique for each record. In such a situation, you can group two or more columns to get the unique values and create an index which is called clustered Index. This also helps you to identify the record faster.
Example:
Let's assume that a company recruited many employees in various departments. In this case, clustering indexing in DBMS should be created for all employees who belong to the same dept.
It is considered in a single cluster, and index points point to the cluster as a whole. Here, Department _no is a non-unique key.
Multilevel Indexing in Database is created when a primary index does not fit in memory. In this type of indexing method, you can reduce the number of disk accesses to short any record and kept on a disk as a sequential file and create a sparse base on that file.

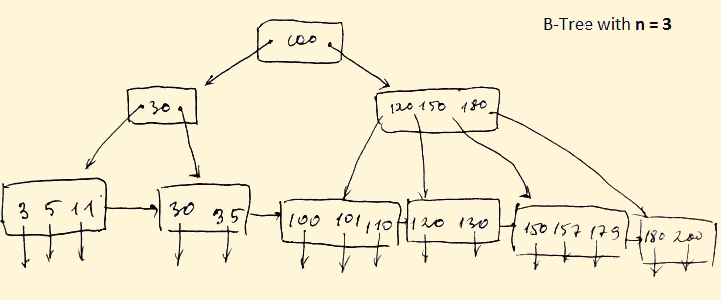
B-tree index is the widely used data structures for tree based indexing in DBMS. It is a multilevel format of tree based indexing in DBMS technique which has balanced binary search trees. All leaf nodes of the B tree signify actual data pointers.
Moreover, all leaf nodes are interlinked with a link list, which allows a B tree to support both random and sequential access.
Important pros/ advantage of Indexing are:
Important drawbacks/cons of Indexing are:
Download PDF 1) Explain what is SQLite? SQLite is a mostly ACID compliant relational database...
What is the UPDATE Query? UPDATE MySQL command is used to modify rows in a table. The update...
SQLite offers a lot of different installation packages, depending on your operating systems. It...
What are MySQL Wildcards? MySQL Wildcards are characters that help search data matching complex...
What is Database Design? Database Design is a collection of processes that facilitate the...
What are Decision-Making Statements? Decision making statements are those who will decide the...