Review

14 BEST Wireless Keyboard & Mouse Combo (2021 Update)
Wireless Keyboard and Mouse enables you to eliminate wires to make your workstation clean and...
MapReduce is a software framework and programming model used for processing huge amounts of data. MapReduce program work in two phases, namely, Map and Reduce. Map tasks deal with splitting and mapping of data while Reduce tasks shuffle and reduce the data.
Hadoop is capable of running MapReduce programs written in various languages: Java, Ruby, Python, and C++. The programs of Map Reduce in cloud computing are parallel in nature, thus are very useful for performing large-scale data analysis using multiple machines in the cluster.
The input to each phase is key-value pairs. In addition, every programmer needs to specify two functions: map function and reduce function.
In this beginner Hadoop MapReduce tutorial, you will learn-
The whole process goes through four phases of execution namely, splitting, mapping, shuffling, and reducing.
Now in this MapReduce tutorial, let's understand with a MapReduce example–
Consider you have following input data for your MapReduce in Big data Program
Welcome to Hadoop Class Hadoop is good Hadoop is bad
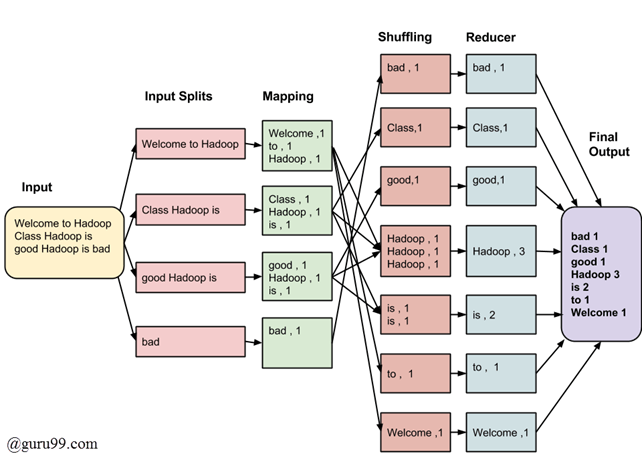
The final output of the MapReduce task is
| bad | 1 |
| Class | 1 |
| good | 1 |
| Hadoop | 3 |
| is | 2 |
| to | 1 |
| Welcome | 1 |
The data goes through the following phases of MapReduce in Big Data
Input Splits:
An input to a MapReduce in Big Data job is divided into fixed-size pieces called input splits Input split is a chunk of the input that is consumed by a single map
Mapping
This is the very first phase in the execution of map-reduce program. In this phase data in each split is passed to a mapping function to produce output values. In our example, a job of mapping phase is to count a number of occurrences of each word from input splits (more details about input-split is given below) and prepare a list in the form of <word, frequency>
Shuffling
This phase consumes the output of Mapping phase. Its task is to consolidate the relevant records from Mapping phase output. In our example, the same words are clubed together along with their respective frequency.
Reducing
In this phase, output values from the Shuffling phase are aggregated. This phase combines values from Shuffling phase and returns a single output value. In short, this phase summarizes the complete dataset.
In our example, this phase aggregates the values from Shuffling phase i.e., calculates total occurrences of each word.
Now in this MapReduce tutorial, we will learn how MapReduce works
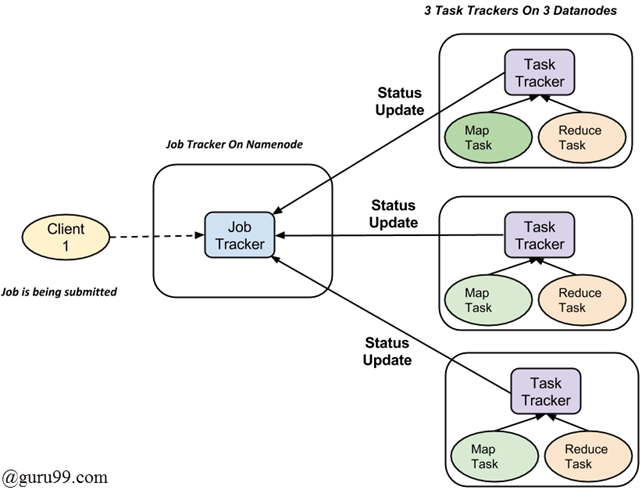
Hadoop divides the job into tasks. There are two types of tasks:
as mentioned above.
The complete execution process (execution of Map and Reduce tasks, both) is controlled by two types of entities called a
For every job submitted for execution in the system, there is one Jobtracker that resides on Namenode and there are multiple tasktrackers which reside on Datanode.
Wireless Keyboard and Mouse enables you to eliminate wires to make your workstation clean and...
Contact Management Software helps you store your contact information and manage your sales and...
What is Entity-Component-System? Entity-Component–System (ECS) is an architectural pattern. This...
Tata Consultancy Services is an Indian multinational information technology company headquartered...
Download PDF 1) Difference between the variables in which chomp function work ? Scalar : It is...
What is a Variable? Variable is a name assign to a storage area that the program can manipulate. A variable...



