SAP - CRM
SAP CRM Pricing & Billing: Elements, Procedure, Type, Web UI
Overview Pricing functionality within SAP CRM is provided by I nternet P ricing and C onfigurator...
Very often, we have data from multiple sources. To perform an analysis, we need to merge two dataframes together with one or more common key variables.
In this tutorial, you will learn
A full match returns values that have a counterpart in the destination table. The values that are not match won't be return in the new data frame. The partial match, however, return the missing values as NA.
We will see a simple inner join. The inner join keyword selects records that have matching values in both tables. To join two datasets, we can use merge() function. We will use three arguments :
merge(x, y, by.x = x, by.y = y)Arguments: -x: The origin data frame -y: The data frame to merge -by.x: The column used for merging in x data frame. Column x to merge on -by.y: The column used for merging in y data frame. Column y to merge on
Example:
Create First Dataset with variables
Create Second Dataset with variables
The common key variable is surname. We can merge both data and check if the dimensionality is 7x3.
We add stringsAsFactors=FALSE in the data frame because we don't want R to convert string as factor, we want the variable to be treated as character.
# Create origin dataframe(
producers <- data.frame(
surname = c("Spielberg","Scorsese","Hitchcock","Tarantino","Polanski"),
nationality = c("US","US","UK","US","Poland"),
stringsAsFactors=FALSE)
# Create destination dataframe
movies <- data.frame(
surname = c("Spielberg",
"Scorsese",
"Hitchcock",
"Hitchcock",
"Spielberg",
"Tarantino",
"Polanski"),
title = c("Super 8",
"Taxi Driver",
"Psycho",
"North by Northwest",
"Catch Me If You Can",
"Reservoir Dogs","Chinatown"),
stringsAsFactors=FALSE)
# Merge two datasets
m1 <- merge(producers, movies, by.x = "surname")
m1
dim(m1)Output:
surname nationality title 1 Hitchcock UK Psycho 2 Hitchcock UK North by Northwest 3 Polanski Poland Chinatown 4 Scorsese US Taxi Driver 5 Spielberg US Super 8 6 Spielberg US Catch Me If You Can 7 Tarantino US Reservoir Dogs
Let's merge data frames when the common key variables have different names.
We change surname to name in the movies data frame. We use the function identical(x1, x2) to check if both dataframes are identical.
# Change name of ` movies ` dataframe colnames(movies)[colnames(movies) == 'surname'] <- 'name' # Merge with different key value m2 <- merge(producers, movies, by.x = "surname", by.y = "name") # Print head of the data head(m2)
Output:
##surname nationality title ## 1 Hitchcock UK Psycho ## 2 Hitchcock UK North by Northwest ## 3 Polanski Poland Chinatown ## 4 Scorsese US Taxi Driver ## 5 Spielberg US Super 8 ## 6 Spielberg US Catch Me If You Can
# Check if data are identical identical(m1, m2)
Output:
## [1] TRUE
This shows that merge operation is performed even if the column names are different.
It is not surprising that two dataframes do not have the same common key variables. In the full matching, the dataframe returns only rows found in both x and y data frame. With partial merging, it is possible to keep the rows with no matching rows in the other data frame. These rows will have NA in those columns that are usually filled with values from y. We can do that by setting all.x= TRUE.
For instance, we can add a new producer, Lucas, in the producer data frame without the movie references in movies data frame. If we set all.x= FALSE, R will join only the matching values in both data set. In our case, the producer Lucas will not be join to the merge because it is missing from one dataset.
Let's see the dimension of each output when we specify all.x= TRUE and when we don't.
# Create a new producer
add_producer <- c('Lucas', 'US')
# Append it to the ` producer` dataframe
producers <- rbind(producers, add_producer)
# Use a partial merge
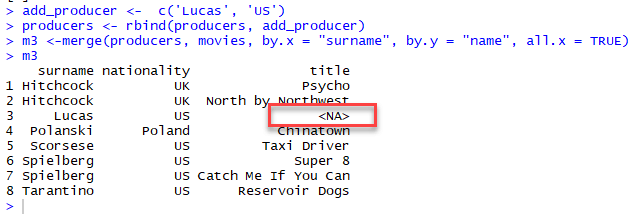
m3 <-merge(producers, movies, by.x = "surname", by.y = "name", all.x = TRUE)
m3Output:
# Compare the dimension of each data frame dim(m1)
Output:
## [1] 7 3
dim(m2)
Output:
## [1] 7 3
dim(m3)
Output:
## [1] 8 3
As we can see, the dimension of the new data frame 8x3 compared with 7x3 for m1 and m2. R includes NA for the missing author in the books data frame.
Overview Pricing functionality within SAP CRM is provided by I nternet P ricing and C onfigurator...
What is MVC? The MVC framework is an architectural pattern that separates an applications into...
Overview CRM WebClient UI is a web based application for the modules covered in SAP CRM. This...
A Partition is a hard drive section that is separated from other parts. It enables you to divide...
What is Server? A server is a central repository where data and computer programs are stored and...
{loadposition top-ads-automation-testing-tools} JMeter is an open source load and performance...