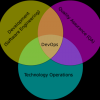
DevOps
Top 50 DevOps Interview Questions & Answers
Download PDF 1) Explain what DevOps is? It is a newly emerging term in the IT field, which is...
Tagging Sentence in a broader sense refers to the addition of labels of the verb, noun,etc.by the context of the sentence. Identification of POS tags is a complicated process. Thus generic tagging of POS is manually not possible as some words may have different (ambiguous) meanings according to the structure of the sentence. Conversion of text in the form of list is an important step before tagging as each word in the list is looped and counted for a particular tag. Please see the below code to understand it better
import nltk text = "Hello gtupapers, You have to build a very good site, and I love visiting your site." sentence = nltk.sent_tokenize(text) for sent in sentence: print(nltk.pos_tag(nltk.word_tokenize(sent)))
OUTPUT
[('Hello', 'NNP'), ('gtupapers', 'NNP'), (',', ','), ('You', 'PRP'), ('have', 'VBP'), ('build', 'VBN'), ('a', 'DT'), ('very', 'RB'), ('good', 'JJ'), ('site', 'NN'), ('and', 'CC'), ('I', 'PRP'), ('love', 'VBP'), ('visiting', 'VBG'), ('your', 'PRP$'), ('site', 'NN'), ('.', '.')]

Code Explanation
In Corpus there are two types of POS taggers:
1.Rule-Based POS Tagger: For the words having ambiguous meaning, rule-based approach on the basis of contextual information is applied. It is done so by checking or analyzing the meaning of the preceding or the following word. Information is analyzed from the surrounding of the word or within itself. Therefore words are tagged by the grammatical rules of a particular language such as capitalization and punctuation. e.g., Brill's tagger.
2.Stochastic POS Tagger: Different approaches such as frequency or probability are applied under this method. If a word is mostly tagged with a particular tag in training set then in the test sentence it is given that particular tag. The word tag is dependent not only on its own tag but also on the previous tag. This method is not always accurate. Another way is to calculate the probability of occurrence of a specific tag in a sentence. Thus the final tag is calculated by checking the highest probability of a word with a particular tag.
Tagging Problems can also be modeled using HMM. It treats input tokens to be observable sequence while tags are considered as hidden states and goal is to determine the hidden state sequence. For example x = x1,x2,............,xn where x is a sequence of tokens while y = y1,y2,y3,y4.........ynis the hidden sequence.
HMM uses join distribution which is P(x, y) where x is the input sequence/ token sequence and y is tag sequence.
Tag Sequence for x will be argmaxy1....ynp(x1,x2,....xn,y1,y2,y3,.....). We have categorized tags from the text, but stats of such tags are vital. So the next part is counting these tags for statistical study.
Download PDF 1) Explain what DevOps is? It is a newly emerging term in the IT field, which is...
Before, we understand Encryption vs. Decryption let's first understand- What is Cryptography?...
What is Continuous Integration? Continuous integration is a software development method where...
As Linux is a multi-user operating system, there is a high need of an administrator, who can...
What is Python Certification? Python certification training courses help you to master the...
Before we learn about MEAN Stack Developer, let's understand- What is Mean Stack? Mean Stack...